Bob Metcalfe, who invented the law in the first place and is my partner at Polaris (and who, along with Al Gore, invented the Internet…), offers his own view in a guest blog post below.
Metcalfe’s original insight was that the value of a communications network grows (exponentially, as it turns out) as the number of users grows.
All seem to agree that Metcalfe’s Law offers a good theoretical framework for thinking about Social Networks. Robertson argues that in addition to the number of users, the rank of a social network is another variable that should be considered when the law is applied to a social network as opposed to a communications network; Stutzman, on the other hand, suggests that one ought to add consideration of “the sum of actions and associations” enabled by a particular social network.
Not surprisingly, Metcalfe himself offers a more insightful and, I think, important contribution to the conversation — that to understand the value of a social network we need to consider not just the number of users but also the affinity between the members of the network.
Enjoy Bob’s post, and by all means please feel free to add your own comments…
Metcalfe’s Law Recurses Down the Long Tail of Social Networking
By Bob Metcalfe
Metcalfe’s Law is under attack again. This latest attack argues that the value of a network does not grow as the square of its number of users, V~N^2, like I’ve been saying for 26 years, but slower, V~N*Log(N). The new attack comes in a cover story by Briscoe, Odlyzko, and Tilly in a prestigious 385,000-member social network called IEEE SPECTRUM. And now they are saying that my law is not just wrong but also “dangerous.”
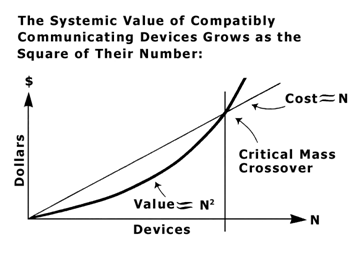
Below is the original not PowerPoint but 35mm slide I used circa 1980 to convince early Ethernet adopters to try LANs large enough to exhibit network effects – networks larger than some “critical mass.”
This slide was named “Metcalfe’s Law” by George Gilder in the September 1993 issue of FORBES and later in his book TELECOSM. Again, thank you, George.
Ethernet’s early adopters took this advice, and so my computer communication compatibility company, 3Com, prospered. Last year, according to IDC, 33 years after Ethernet’s invention at Xerox Parc, a quarter billion new Ethernet switch ports were shipped worldwide.
And now for some inconvenient truths. Al Gore famously claimed to have invented the Internet in the 1980s, which struck some of us as a little late. Like his father, Al Gore Senior, who claimed to have invented what is inexplicably called the Eisenhower Interstate Highway System, Al Gore Junior invented what he called the Information Superhighway. The actual Internet was invented, I think, either by BBN at UCLA in 1969 or at Stanford in 1973.
With his Information Superhighway, Gore invented not the Internet but the Internet … Bubble. I was present when Vice President Gore mentioned Metcalfe’s Law in an MIT commencement address, inflating his administration’s Internet Bubble. I helped Gore inflate the Internet Bubble by touting Metcalfe’s Law. I am not sorry.
There are people who think the Internet Bubble was the worst thing that ever happened, and I hope those people are satisfied now that Ken Lay is dead. To those people my law may be, as the SPECTRUM article says, dangerous.Because my law allegedly over-estimates the values of networks, it might be used to inflate a second Internet Bubble, probably the imminent Social Networking Bubble, which will then inevitably burst. Can’t have that.
So, in IEEE SPECTRUM, Briscoe, Odlyzko, and Tilly debunk Metcalfe’s Law, again. It turns out that the value of a network does not grow as the square of the number of its users, V~N^2, but much more slowly, V~N*log(N), they figure.Cold water can now be thrown on the promoters of social networking. The bursting of a second Internet Bubble is thereby averted.
In renewed defense of Metcalfe’s Law, let me first point out that Al Gore has moved on to the invention of Global Warming. If a second Internet Bubble is to be inflated, I will have to do it without Gore’s hot air this time… Let’s get started.
Let me contrast Metcalfe’s Law with
Moore’s Law. Moore’s and Metcalfe’s Laws are similar in that both begin with the letter M. They are different in that
Moore’s Law is exponential in time while Metcalfe’s Law is quadratic in size.
Moore‘s Law, which states that semiconductors double in complexity every two years, has been numerically accurate since 1965. Metcalfe’s Law, on the other hand, has never been evaluated numerically, certainly not by me.
Nobody, including Briscoe, Odlyzko, and Tilly in their SPECTRUM attack, has attempted to estimate what I hereby call A, network value’s constant of proportionality in my law, V=A*N^2. Nor has anyone tried to fit any resulting curve to actual network sizes and values.
As I wrote a decade ago, Metcalfe’s Law is a vision thing. It is applicable mostly to smaller networks approaching “critical mass.” And it is undone numerically by the difficulty in quantifying concepts like “connected” and “value.”
So, if the value of a network does grow as V~N*log(N), I challenge Briscoe, Odlyzko, and Tilly to prove it with some real network sizes and values. In the meantime, I’ll stick with V~N^2.
While they’re at it, my law’s critics should look at whether the value of a network actually starts going down after some size. Who hasn’t received way too much email or way too many hits from a Google search? There may be diseconomies of network scale that eventually drive values down with increasing size. So, if V=A*N^2, it could be that A (for “affinity,” value per connection) is also a function of N and heads down after some network size, overwhelming N^2. Somebody should look at that and take another crack at my poor old law.
But, if anybody wants to spend time on Metcalfe’s Law, let me suggest what are likely to be more fruitful paths. Accurate formulas for the static value of a network are fine, but it would be much more useful to understand the dynamics of network value over time. Also important would be linking Metcalfe’s Law to
Moore’s Law and showing how that potent combination underlies what WIRED’s Editor-in-Chief Chris Anderson calls The Long Tail.
Metcalfe’s Law points to a critical mass of connectivity after which the benefits of a network grow larger than its costs. The number of users at which this critical mass is achieved can be calculated by solving C*N=A*N^2, where C is the cost per connection and A is the value per connection. The N at which critical mass is achieved is N=C/A. It is not much of a surprise that the lower the cost per connection, C, the lower the critical mass number of users, N. And the higher the value per connection, A, the lower the critical mass number of users, N.
Continuing to paint with a broad brush, I take
Moore’s Law to mean that my law’s connectivity cost C — the cost of the computing and communication used to create connectivity — is halved every two years. Combining Moore’s and Metcalfe’s Laws, therefore, the number of users at which a network’s value exceeds its cost halves every two years. And that’s just considering C.
I am reminded that the first Ethernet card I sold at 3Com in 1980 went for $5,000. By 1982, the cost was down to $1,000. Today, Ethernet connections cost under $100, perhaps as low as $5 per connection. Whatever the critical mass sizes of Ethernets were in 1980, they are a lot lower now.
But that’s not all. The denominator of C/A, the constant of value proportionality, A, has been going up. In the 1980s, Ethernet connectivity allowed users only to share printers, share disks, and exchange emails — a very low A indeed. But today, Internet connectivity brings users the World Wide Web, Amazon, eBay, Google, iTunes, blogs, … and social networking. The Internet’s value per connection, A, is a lot higher now, which means the critical mass size of the Internet, C/A, is a lot lower now, and for two reasons: cost and value.
Amazon connectivity among people and books allows my five-year-old book, INTERNET COLLAPSES, to be available still, with Amazon rank below 1,000,000. There’s eBay connectivity among people with ever more arcane things to buy and sell. There’s blogosphere connectivity among many more writers each with many fewer readers. Daily newspaper circulations have been going down since 1984, and there are now millions of active blogs, most of them very small. Blogs are an early form of social networking among growing numbers of smaller groups along ever more refined dimensions of affinity.
Social networks form around what might be called affinities. For each affinity, there is a critical mass size given by N=C/A, as above. If the number of people sharing an affinity is above this critical mass, then their social network may form, otherwise not. As Internet access gets cheaper and the tools for exploiting affinities get better, many more social networks will become viable.
Somebody should look at this. Somebody already has: Chris Anderson.
Moore’s and Metcalfe’s Laws bring us to Chris Anderson’s new book, THE LONG TAIL, which you should read immediately. (Actually, there’s no rush.
Anderson’s book currently has double-digit rank at Amazon, like my book did five years ago. Take your time and you might even get THE LONG TAIL for next to nothing as it moves down Amazon’s Long Tail.)
Anderson‘s Long Tail explains how, for example, more people are listening to music other than the Top 40 hits. Thanks to iTunes, even though there still is a Top 40, the fraction of music listening from down music’s Long Tail is increasing. It remains to be seen whether the growth of music’s Long Tail increases total music sales, which would be my guess, or whether it shifts revenues away from Britney Spears.
For another example of The Long Tail, millions of books like mine, which would otherwise be out of print, can still be found at Amazon.com and delivered in a day or two. Try buying INTERNET COLLAPSES, used if you must.
Let me leave as an exercise for the reader to develop the formulas for how Amazon’s Long Tail grows to the right as the combination of Moore’s and Metcalfe’s Laws biennially halves the critical-mass size of book audiences. Book buying generally shrinks with time, but I’m guessing that Amazon’s per book critical masses, its N=C/As, have been shrinking faster.
Similar formulas could quantify how Moore’s and Metcalfe’s Laws have also driven down the critical mass sizes (N=C/A) of Internet-enabled social networks and extended their Long Tail to the right. Looking more closely, I see that Metcalfe’s Law recurses. Just being on the Internet has some increasing value that may be described by my law. But then there’s the value of being in a particular social network through the Internet. It’s V~N^2 all over again. Down a level, N is now the number of people in a particular social network, which has its own C, A, V, and critical mass N.
Of course the cost (C*N) of getting connected in a social network has been going down thanks to the proliferation of the Internet and its decreasing price.The value (A*N^2) of particular social networks has been growing with broadband and mobile Internet access. Emerging software tools expedite the viral growth and ease of communication among network members, also boosting the value of underlying connectivity.
So, if you want to spend time on V~N^2, and I hope you do, then forget minor refinements like V~N*log(N) and help inflate the next Internet Bubble by figuring out how Metcalfe’s Law recurses down The Long Tail of social networking.
Bob Metcalfe received the National Medal of Technology from President Bush in 2005 for his leadership in the invention, standardization, and commercialization of Ethernet. Bob is a general partner of Polaris Venture Partners, where he serves on the boards of Polaris-back companies including Ember, GreenFuel, Infinite Power Solutions, Mintera, Narad, Paratek Microwave, and SiCortex.





 3:30
3:30
 Juan MC Larrosa
Juan MC Larrosa


 About the Author: Kalliopi Monoyios is the illustrator of several best-selling science books including Neil Shubin's The Universe Within, Shubin’s Your Inner Fish, and Jerry Coyne’s Why Evolution is True. Her illustration portfolio can be found at kalliopimonoyios.com. Follow her solo on Twitter at @eyeforscience. For tweets from the whole Symbiartic crew, Follow on Twitter @symbiartic.
About the Author: Kalliopi Monoyios is the illustrator of several best-selling science books including Neil Shubin's The Universe Within, Shubin’s Your Inner Fish, and Jerry Coyne’s Why Evolution is True. Her illustration portfolio can be found at kalliopimonoyios.com. Follow her solo on Twitter at @eyeforscience. For tweets from the whole Symbiartic crew, Follow on Twitter @symbiartic.